I also installed the bookdown package in R, in order to be able to cross-reference tables (then the YAML output document type is bookdown::pdf_document2)
I also installed the knitr and kableExtra packages, in order to be able to create the tables themselves using the kable() function
🍁 A Canadian example! 🍁
Now I’ll go through an example that uses all of the techniques I used while I was writing the report!
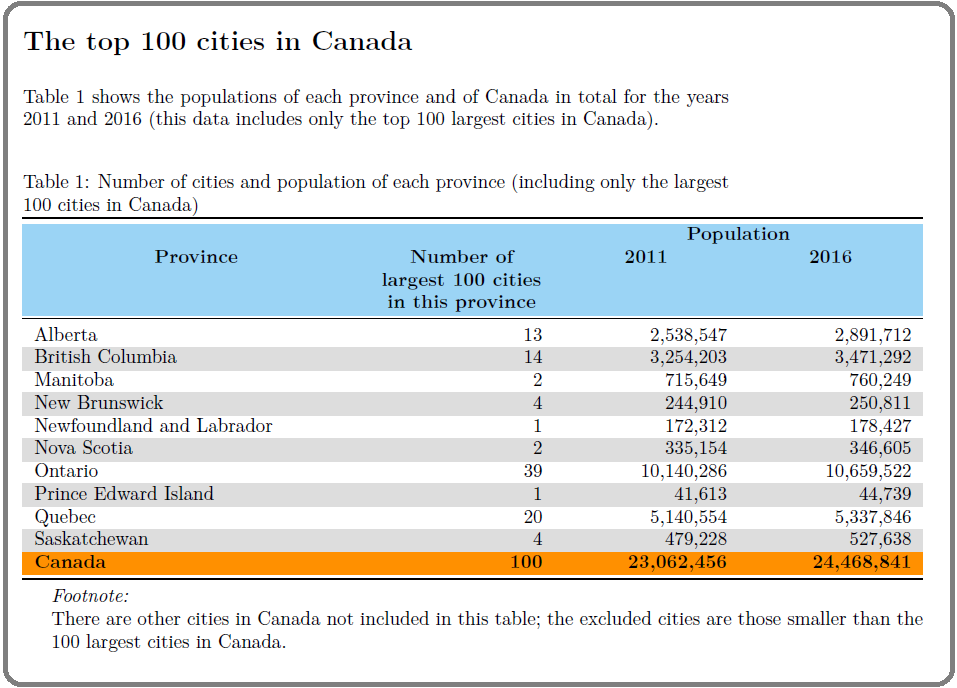
the number of cities in each province that are in the top 100
the population of each province in 2011 and 2016 (including the populations of the top 100 cities only)
a “Total” row for Canada that shows the total number of cities (this number should equal 100)
the population of Canada in 2011 and 2016 (including the populations of the top 100 cities only)
I used the website Convert Wiki Tables to CSV to turn the table on the Wikipedia page into a CSV file. Click here to see the full raw file on my Github page.
Data import
Here is the R code where I import the CSV file I created ("wiki_data.csv"). Underneath the code, I’ve displayed what the raw data file looks like.
# A tibble: 6 × 7
rank population_centre province population_in_2016 population_in_2011
<dbl> <chr> <chr> <dbl> <dbl>
1 1 "Toronto" Ontario 5429524 5144412
2 2 "Montreal" Quebec 3519595 3387653
3 3 "Vancouver" British Colu… 2264823 2124443
4 4 "Calgary" Alberta 1237656 1094379
5 5 "Edmonton" Alberta 1062643 935361
6 6 "Ottawa\x96Gatineau" Ontario/Queb… 989657 945592
# ℹ 2 more variables: percent_change <chr>, class <chr>
Data cleaning
I am only interested in the province of each city and what its population was in 2011 and 2016, so my first step in cleaning will be to select only those three columns. I will then use group_by and summarize to get the number of cities and populations on a per-province basis.
wiki_data_by_province <- wiki_data_raw %>%select(province,population_2016 = population_in_2016,population_2011 = population_in_2011) %>%# Since some provinces were actually two provinces put together# (e.g., "Alberta/Saskatchewan"), I used regex code from this website# (https://www.perlmonks.org/?node_id=908348) to get everything before# the first forward slash in the stringmutate(province =str_extract(province, "^([^\\/]+)")) %>%group_by(province) %>%summarize(number_of_cities_in_top_100 =n(),pop_of_largest_cities_2011 =sum(population_2011),pop_of_largest_cities_2016 =sum(population_2016))wiki_data_by_province
Since I also want a “Total” row for all of Canada, I will take the above wiki_data_by_province tibble and I will summarize the three columns in a new tibble to get the total sums for the number of cities and their populations in 2011 and 2016. Since using summarize means I lose the province variable, I will recreate it using mutate to have a value of “Canada”.
Now I want to merge both the wiki_data_by_province tibble and the wiki_data_total_row tibble on top of one another (using bind_rows). This will be the table that I will save and then read into my .Rmd file in order to create the table in PDF.
wiki_data_final_table <- wiki_data_by_province %>%bind_rows(wiki_data_total_row) %>%# This mutate_at# (created using code from https://suzan.rbind.io/2018/02/dplyr-tutorial-2/#mutate-at-to-change-specific-columns)# converts all variables containing the word "pop" to have commas separating the thousands.mutate_at(vars(contains("pop")),list(. %>% scales::comma()))wiki_data_final_table
Below is the .Rmd file that reads in the wiki_data_final_table tibble and uses the kable and kableExtra packages in order to get the table to look the way I want it to.
Also, notice that in the YAML, my output format is bookdown::pdf_document2. This allows me to cross-reference my tables with the text of my document.
So, what’s the real secret to creating tables in PDF from RMarkdown?
❗**To see the final PDF of the below .Rmd file, click here❗
---title:'The top 100 cities in Canada'output: bookdown::pdf_document2: toc: no number_sections:FALSE keep_tex:TRUEalways_allow_html: yesgeometry:"left=1.5cm,right=7cm,top=2cm,bottom=2cm"---{r setup, include=FALSE}knitr::opts_chunk$set(echo =FALSE,warning =FALSE,message =FALSE,out.width="8.5in")library(dplyr)library(knitr)library(kableExtra)# Colours for the tableblue_table_colour <-"#9BD4F5"orange_table_colour <-"#FF9000"light_striping_table_colour <-"#DDDDDD"{r import-cleaned-data}wiki_data_final_table <-readRDS(here::here("posts","2019-09-01-tables-in-pdf","cleaned_wiki_data_for_table.rds"))Table @ref(tab:table-population-by-province) shows the populations of each province and of Canada in total for the years 2011 and 2016 (this data includes only the top 100 largest cities in Canada).{r table-population-by-province}wiki_data_final_table %>% knitr::kable("latex",booktabs =TRUE,linesep ="",caption ="Number of cities and population of each province (including only the largest 100 cities in Canada)",col.names =c("Province", "Number of largest 100 cities in this province", rep(c("2011", "2016"), 1)),align =c("l", rep("r", 3))) %>%kable_styling(latex_options ="HOLD_position") %>%# This line holds the table where you want it, so LaTeX won't move it aroundadd_header_above(c(" "=1, # There has to be a space here, like this " ", and not like this """ "=1,"Population"=2),bold =TRUE,line =FALSE,background = blue_table_colour ) %>%column_spec(1,width ="6cm") %>%column_spec(2:4,width ="3cm") %>%footnote(general ="There are other cities in Canada not included in this table; the excluded cities are those smaller than the 100 largest cities in Canada.",threeparttable =TRUE,general_title ="Footnote:") %>%row_spec(row =0,background = blue_table_colour,bold =TRUE,align ="c" ) %>%row_spec(row =c(2,4,6,8,10),background = light_striping_table_colour ) %>%row_spec(row =11,background = orange_table_colour,bold =TRUE ) %>%row_spec(row =10,hline_after =TRUE) # This hline unfortunately gets hidden by the orange colouring of the final row, so this line of code doesn't really do anything :(